
Quelles différences entre un crawl SEO et le crawl d’un moteur de recherche ?
Les moteurs de recherche et les SEOs se servent tous les deux d’un robot, ou crawler, pour parcourir des URLs. C’est grâce au crawl qu’ils peuvent analyser les pages et leur contenu. Néanmoins, les robots SEO et ceux des moteurs de recherche ont des différences importantes de fonctionnement.
1. La découverte des pages
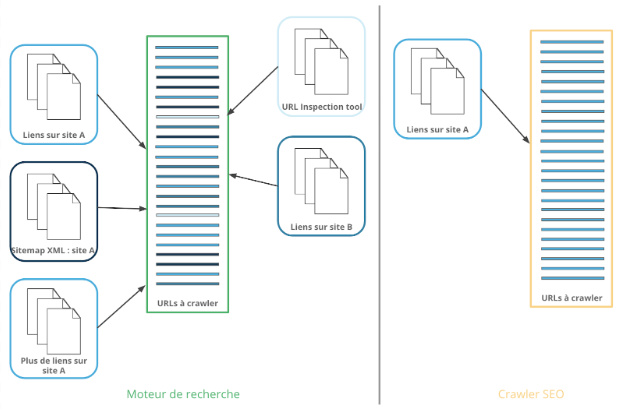
Pour découvrir de nouvelles pages sur Internet, un moteur de recherche se sert de différentes sources d’information.
Google, par exemple, découvre des URLs grâce aux :
- liens rencontrés pendant ses crawls sur les pages connues sur n’importe quel site
- URLs dans un sitemap XML
- URLs soumises via l’outil d’inspection d’URL
De plus, d’autres moteurs de recherche comme Bing permettent de fournir par API une liste d’URLs.
Les URLs de toutes ces sources sont ajoutées à la liste de pages à crawler.
Par contre, un robot SEO ne découvre des URLs que par le crawl à travers la structure de votre site web. Cela donne au robot SEO une vision plus restreinte de votre site. Une landing page Adwords sans liens internes entrants, mais qui a servi comme page d’atterrissage d’une campagne sur les réseaux sociaux, par exemple, sera inconnue aux yeux des bots SEO… mais sera rapidement trouvée par un moteur de recherche !
2. La temporalité d’exploration
Pas toutes à la fois !
Les URLs connues d’un moteur de recherche sont ajoutées à une liste pour être crawlées. Comme nous avons vu, elles proviennent de sources différentes. Les pages séquentielles sur votre site ne se trouveront peut-être pas ensemble dans cette liste. Pour le confirmer, jetez un oeil aux visites des bots dans vos fichiers de log.
Google a indiqué que, par session de crawl sur un site, différents éléments peuvent limiter le nombre de pages crawlées :
- Google ne crawle pas plus de 5 maillons d’une chaîne de redirections par session
- Google peut raccourcir une session de crawl si le serveur de votre site web ne répond pas assez rapidement.
De plus, il priorise les pages dans la liste de pages à crawler. La source de la page, les facteurs d’importance du site ou de la page, les métriques liés à la fréquence de publication, et d’autres éléments peuvent faire « monter » une URL dans la liste des pages à crawler.
Un robot SEO n’a que les pages connues de votre site web dans sa liste d’URLs à crawler. Par conséquent, il les crawl les unes après les autres. Souvent, les crawlers SEO suivent le maillage des liens internes du site : ils crawlent toutes les pages à 1 clic de la page où ils ont commencé, puis toutes les pages à 2 clics, puis toutes les pages à 3 clics et cela dans l’ordre de découverte des pages.
Par conséquent, contrairement à Google, un robot SEO trop rapide peut arriver à saturer un site web avec un nombre trop important de demandes d’URL trop rapprochées dans le temps.
Indexation en deux temps
Pour les pages qui comprennent des éléments en Javascript, le robot doit exécuter le code et rendre la page afin de voir le contenu inséré par le script. Cela n’est pas réalisé par le robot d’exploration et de crawl d’un moteur de recherche. Les pages qui ont besoin d’être rendues sont ajoutées à une liste de rendu ; celui-ci a lieu plus tard.
Cela veut dire qu‘une page est souvent crawlée et indexée par Google sans ses composants Javascript. Le plus souvent, l’indexation est mise à jour assez rapidement pour prendre en compte les éléments additionnels découverts lors du rendu.
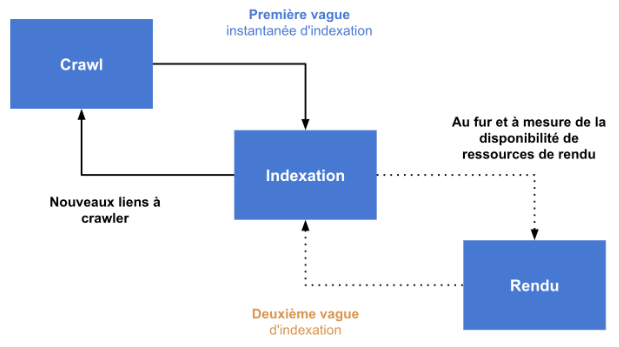
Cette indexation en deux temps peut poser des problèmes lorsque du contenu clé, comme par exemple les liens, les indications par rapport aux langues ou aux URLs canoniques, ou encore la description meta, est inséré dans la page par Javascript.
Les bots SEO ne sont pas tous faits pareil. Certains ne sont pas capables de réaliser le rendu d’une page qui incorporent du Javascript. Dans ce cas, le contenu apporté par le Javascript n’est pas accessible.
D’autres crawlers font, comme Google, un rendu des pages contenant du JavaScript. Contrairement au procédé de Google, cela est fait le plus souvent pendant le crawl principal : il n’y a pas de deuxième passe pour le rendu. Cela veut dire qu’un rendu très lent peut retarder le crawl de l’URL suivante dans la liste, et ainsi de suite.
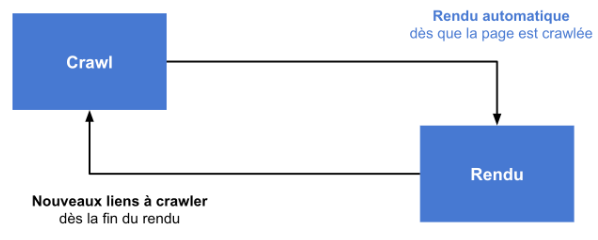
L’avantage : pour le crawler SEO qui comprend le rendu, les contenus insérés par Javascript ne sont jamais perdus !
3. Limites
Le crawl de Google est récurrent : bien que le budget de crawl de Google limite la fréquence des visites des Googlebots (c’est-à-dire le nombre de pages crawlées par Google dans une période donnée), après avoir crawlé quelques pages sur votre site, Google revient plus tard pour les revisiter ou pour en parcourir d’autres.
Sur Google, une page récente peut se trouver indexée rapidement, tandis que d’autres pages, mises à jour avant que celle-là soit publiée, sont toujours indexées dans leur version antérieure jusqu’à ce que le robot y retourne pour découvrir les modifications.
En dehors des directives que vous pouvez donner aux bots via les balises meta robots, les robots.txt et les fichiers htaccess, les moteurs de recherche n’arrêtent jamais de visiter un site et découvriront à terme certaines pages non vues (ou pas encore publiées) lors de leurs premières visites.
Un robot SEO, lui, ne met pas constamment à jour sa liste de pages connues et explorées. Il fournit une capture de toutes les pages du site qui sont accessibles au moment de son passage unique.
Même s’il s’arrête lorsqu’il aura crawlé toutes les pages connues, un crawl SEO peut durer trop longtemps pour être exploitable dans les cas où Google aurait renoncé ou découpé l’exploration en plusieurs séances :
- Vitesse de crawl très lent
- Nombre très important de pages à crawler
- Pièges à robots qui créent une liste sans fin de pages à crawler
Pour éviter un crawl qui ne termine jamais, la plupart de crawlers SEO permettent d’arrêter le robot dans les conditions suivantes :
- Lorsqu’un nombre maximal d’URLs ont été crawlées
- Lorsqu’une profondeur (en nombre de clics depuis l’URL de début) maximale a été atteinte
- Lorsque l’utilisateur a décidé d’interrompre le crawl
Cela peut produire des crawls « incomplets » du site où le robot a connaissance de l’existence d’URLs supplémentaires qu’il n’a pas crawlées.
4. Respect du robots.txt et des directives meta
La plupart des moteurs de recherche respectent les instructions aux robots : si, dans les directives meta des pages ou dans le fichier robots.txt, une page ou un dossier est interdit aux robots, ils n’y vont pas.
La seule difficulté est de savoir quelles pages le robot doit visiter, et comment exprimer cela selon les règles complexes du fichier robots.txt.
Un robot SEO n’a pas, en théorie, de restriction. La plupart des crawlers SEO proposent des bots respectueux, comme ceux des moteurs de recherche.
Mais cela peut poser un problème pour les marketeurs qui souhaitent savoir comment Google voit leur site : les instructions aux robots pouvant cibler un robot en particulier, un robot non-Google n’aura pas les mêmes accès qu’un robot Google.
5. User-Agent
Les moteurs de recherche crawlent avec un User-Agent, un profil qui leur sert d’identifiant, bien défini :
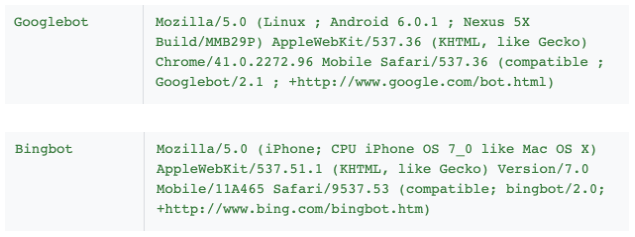
Les règles robots.txt et meta robots peuvent cibler un robot spécifique grâce à son User-Agent.
Exemple de robots.txt pour Googlebot uniquement :
User-agent: googlebot
disallow: /private/
disallow: /wp-login.php
disallow: /wp-trackback.php
Exemple de meta robots pour Googlebot uniquement :
<meta name= »googlebot » content= »noindex, nofollow »>
Un robot SEO parcourt votre site avec sa propre identité et ne répond donc pas aux directives spécifiques des autres robots.

Cela veut dire qu’il aura peut-être une vue et une expérience différente sur votre site que le robot d’un moteur de recherche.
6. Nouveaux crawls
Google (ainsi que d’autres moteurs de recherche) revient périodiquement visiter les pages d’un site web. Cela a pour but de vérifier si des éléments de la page ont subi des modifications :
- Est-ce qu’un statut HTTP temporaire (503, 302…) a évolué ?
- Est-ce que le contenu a été mis à jour ?
- Est-ce qu’une erreur a été corrigé (404) ?
- Est-ce qu’une nouvelle indexation a été demandée via la Search Console ?
- Est-ce que la page est candidate pour une meilleure position dans les pages de résultats ?
Un robot SEO, lors d’un audit du site, ne passe qu’une fois sur chaque URL.
Les astuces pour les rapprocher
Bien que les deux types de robots soient différents, les différences ne sont jamais impossibles à résoudre !
La découverte de pages
- Profitez des crawlers SEO qui offrent d’autres options de découverte de pages : listes d’URLs, sitemaps, connexions à d’autres outils, analyse de fichiers logs…
- Privilégiez les analyses comprenant les backlinks, ou liens entrants issus d’autres sites, ainsi que les robots SEO qui sont capables de relever le code du statut HTTP de la réponse des liens sortants, afin que vous puissiez identifier les liens sortants cassés.
La temporalité
- Pour les audits SEO, il faut trouver la bonne vitesse de crawl : assez vite pour obtenir une analyse rapidement, mais assez raisonnable pour que le serveur du site puisse suivre les demandes du robot et des visiteurs humains du site.
- Pensez à faire plusieurs crawls du même site et à les comparer afin de révéler les éléments qui évoluent régulièrement sur ce site.
- Si le site s’appuie sur du Javascript, la comparaison entre un crawl sans rendu Javascript et un crawl avec rendu Javascript peut être révélateur de la source de problèmes d’indexation.
Les limites du crawl
- Il vaut mieux lancer des crawls réguliers ou même programmés pour obtenir une idée de l’évolution d’un site.
- Dans certains cas — comme le cas d’un site multilingue avec des traductions dans d’autres domaines ou sous-domaines — , il peut être important de vérifier que le robot SEO parcourt tous les sous-domaines, ou de le lancer sur plusieurs domaines en même temps.
Les instructions aux robots et l’identité du bot
Deux contournements principaux sont proposés par les crawlers SEO pour rapprocher les comportements des bots SEO et Google :
- Possibilité d’ignorer le vrai fichier robots.txt du site et de prendre en compte des règles robots.txt spécifiques au crawl SEO.
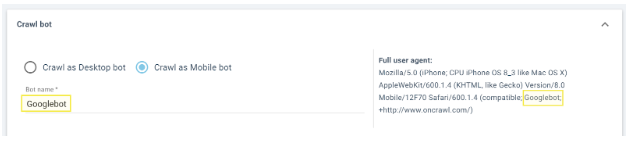
- Possibilité de modifier tout ou une partie de l’identité du robot pour le « déguiser » en robot de moteur de recherche. Par exemple, il est possible de remplacer le nom dans le User-Agent du bot OnCrawl par « Googlebot » :
Les nouveaux crawls
- Imitez le comportement du robot des moteurs de recherche en répétant ou en programmant des crawls subséquents de votre site.
A propos de l’auteur

Rebecca travaille comme Content Manager chez OnCrawl. Elle est passionnée de NLP, de modèles informatiques de langages, des systèmes et de leur fonctionnement général. Rebecca n’est jamais à cours de curiosité lorsqu’il s’agit de sujets SEO technique. Elle croit en l’évangélisation de la technologie et l’utilisation des données pour comprendre la performance des sites web sur les moteurs de recherche.