Robots.txt : comprendre et bien construire son fichier
Lucas Perrosé . 31 juillet 2014
Nous vous en parlions récemment suite à l’enrichissement des Google Webmaster Tools, le fichier robots.txt est un élément important dans la construction d’un site qui est très régulièrement oublié. Et pourtant, en s’adressant directement aux spiders des moteurs, il autorise de nombreuses possibilités.
Le fichier robots.txt, c’est quoi ?
Il s’agit très concrètement d’un fichier texte inséré à la racine de votre site et listant un nombre de consignes pour les robots des moteurs de recherche (d’où son nom, « robots.txt »). Il permet donc de guider le passage des crawlers sur votre site grâce à deux formules assez simples :- User-agent : qui permet de préciser à quel crawler la consigne s’applique (Googlebot, Bingbot, ou bien tous les spiders d’un coup). Exemple : User-agent: * permet de donner des indications à tous les robots.
- Disallow : une commande qui indique aux robots de ne pas circuler sur telle page, dans tel répertoire, etc… Par exemple : Disallow: /images/ interdit aux spiders de parcourir le dossier images.
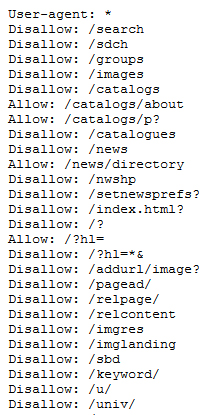 Un exemple de ce que l’on peut trouver dans un fichier robots.txt (ici, celui de Google : http://www.google.fr/robots.txt)
Un exemple de ce que l’on peut trouver dans un fichier robots.txt (ici, celui de Google : http://www.google.fr/robots.txt)
Pourquoi utiliser un fichier robots.txt ?
Dans l’idéal, tous les sites internet devraient avoir un fichier robots.txt, or, ils sont encore extrêmement nombreux à l’oublier, purement et simplement. Et pourtant, indiquer aux robots où ils peuvent ou non se rendre présente deux grands avantages :- Améliorer la sécurité du site, en interdisant l’indexation de données confidentielles, comme par exemple les coordonnées de clients, etc…
- Maitriser l’indexation, ce qui évite de référencer des pages peu pertinentes (comme des Mentions Légales ou des Conditions Générales de Vente) ou encore de créer du duplicate content en laissant les crawlers passer sur des pages au contenu identique,… Cette maitrise de l’indexation est particulièrement importante dans une stratégie SEO.
Ne pas confondre robots.txt et la balise noindex
Pour contrôler l’indexation de son site et de ses contenus, il est également possible d’utiliser la balise appelée noindex. Comme son nom l’indique assez bien, elle interdit aux robots d’indexer la page sur laquelle elle est placée. Si une page est en disallow pour les crawlers, les robots peuvent toutefois connaitre son existence si un lien pointe vers elle (comme précisé plus, son URL est indexée, mais pas son contenu). A l’inverse, si la page est en noindex, aucun robot n’indexera son URL, même si des liens pointent dessus. On comprend alors l’aspect plus « radical » de la balise noindex. Mais alors, pour protéger ses contenus et trier l’indexation de ses pages, faut-il utiliser la balise ou le fichier ? Ou bien les deux ? Tout dépend de l’objectif :- Pour désindexer tout un site, être certain qu’aucun robot ne naviguera dans son code, placer une baliser noindex sur toutes les pages est une solution bien efficace.
- Pour désindexer certaines pages, le fichier robots.txt peut suffire. Toutefois, pour en être certain de son efficacité, mieux vaut aussi placer la balise sur ces pages.
- Pour interdire le passage dans des dossiers ou des répertoires, ici le fichier robots.txt s’impose, car impossible d’y placer une balise noindex.